建议先看看前言:http://www.wutianqi.com/?p=2298
因为《算法导论》第一部分1~5章的理论性太强,研究过多容易纠结,所以索性合起来快点讲过去。
第四章:
这一章讲的是递归式(recurrence),递归式是一组等式或不等式,它所描述的函数是用在更小的输入下该函数的值来定义的。
本章讲了三种方法来解递归式,分别是代换法,递归树方法,主方法。
1.代换法(Substitution method)(P38~P40)
定义:即在归纳假设时,用所猜测的值去代替函数的解。
用途:确定一个递归式的上界或下界。
缺点:只能用于解的形式很容易猜的情形。
总结:这种方法需要经验的积累,可以通过转换为先前见过的类似递归式来求解。
2.递归树方法(Recursion-tree method)
起因:代换法有时很难得到一个正确的好的猜测值。
用途:画出一个递归树是一种得到好猜测的直接方法。
分析(重点):在递归树中,每一个结点都代表递归函数调用集合中一个子问题的代价。将递归树中每一层内的代价相加得到一个每层代价的集合,再将每层的代价相加得到递归式所有层次的总代价。
总结:递归树最适合用来产生好的猜测,然后用代换法加以验证。
递归树扩展过程:①.第二章2.3.2节分析分治法时图2-5(P21~P22)的构造递归树过程;②.第四章P41图4-1的递归树构造过程;这两个图需要好好分析。
3.主方法(Master method)
优点:针对形如T(n) = aT(n/b) + f(n)的递归式
缺点:并不能解所有形如上式的递归式的解。
具体分析:
T(n) = aT(n/b) + f(n)描述了将规模为n的问题划分为a个子问题的算法的运行时间,每个子问题的规模为n/b。
在这里可以看到,分治法就相当于a=2, b=2, f(n) = O(n).
主方法依赖于主定理:(图片点击放大)
 图片可以不清晰,可以看书。
图片可以不清晰,可以看书。
主定理的三种情况,经过分析,可以发现都是把f(n)与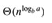 比较。
比较。
第一种情况是 更大,第二种情况是
更大,第二种情况是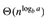 与f(n)相等,第三种情况是f(n)更大。
与f(n)相等,第三种情况是f(n)更大。
但是,这三种情况并未完全覆盖所有可能的f(n):
第一种情况是f(n)多项式的小于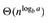 ,而第三种情况是f(n)多项式的大于
,而第三种情况是f(n)多项式的大于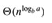 ,即两者相差的是
,即两者相差的是 。如果两者相差的不是
。如果两者相差的不是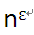 ,则无法用主定理来确定界。
,则无法用主定理来确定界。
比如算法导论P44最下面的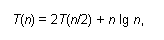 就不能用主定理来判断。
就不能用主定理来判断。
至于主定理的证明,有兴趣的可以拿笔在纸上推算,反正我这里是没看的,毕竟时间有限,要选择性的学习。
第五章:
本章是围绕一个雇佣问题展开的。
问题:有一批参与面试的人,你要一个个面试(面试每个人都要花费c1),如果当前面试者比自己的助理能力强,则辞掉当前助理的,并把当前面试者提拔为助理(雇佣一个人要花费c2),一直面试完所有人。
这里考虑的是面试所花的money,假设总共有N人参加面试,有M人被雇佣过,则花费O(Nc1 + Mc2),因为参与面试的人员顺序是不确定的,所以要花费的money也是不确定的(Nc1是确定的,而M是不确定的,所以Mc2也是不确定的)。
首先介绍两个概念:
1.概率分析:指在问题的分析中应用概率的技术。
2.随机算法:如果一个算法的行为不只是由输入决定,同时也由随机数生成器所产生的数值决定,则成这个算法是随机的。
书上讲的理论性有点强,我这里用自己的话来说下:
首先说下概率分析,因为前面讲到过:雇佣所需的花费与输入序列有关,有N个面试人员(考虑每个人的能力不一样),则一共有N!中排列情况(即每种排列出现的概率是1/(N!)),于是假设每种排列花费Ti元,则所有供花费:
T1/(N!) + T2/(N!) + … + TN/(N!)。
其实这里可以结合高中学的正态分布来理解,都是讲的每种情况出现的概率,思想差不多,所以这里也不需要什么概率论的知识,都是一些常识。
顺便补充一下:5.2节的指示器随机变量就是用的高中学的期望,用期望来表示概率。
再说下随机算法,对于上面概率分析时的方法,虽然面试人员的排列是不确定的。但是如果当排列确定后,则所需花费也就确定了。而对于随机算法,就算排列确定,其花费也是不确定的。即随机发生在算法上,而不是发生在输入分布上。这就是概率分析与随机算法之间的区别。
比如按书上的,可以给每个人员随机生成一个优先级,或者把每一个面试人员与其后的面试人员中随机一员交换,来产生一个随机的序列。
我以前总结过一些随机算法,有兴趣的朋友可以去看看:
3.《随机化算法(3) — 舍伍德(Sherwood)算法》
4.《随机化算法(4) — 拉斯维加斯(Las Vegas)算法》
5.《随机化算法(5) — 蒙特卡罗(Monte Carlo)算法》
另外,比如像C/C++中库函数rand()就是一个产生随机变量的函数,但是它并不是真正意义上的随机函数,所以称之为伪随机函数。因为当srand(seed)设置的seed一样时,则rand()产生的随机数也一样,所以通常可以通过rand(-1)来把当前时间作为种子模拟随机函数。
补充:在第五章的5.4节给出了几个题目及其分析,这几个题目都很有趣,不过对于数学也相对有一定的要求。其实可以很简化的想:概率和期望是互相转化的,这几题就可以考虑是去求期望的。
我昨天在论坛出了一个逻辑面试题:一楼到十楼的每层电梯门口都放着一颗钻石,钻石大小不一。你乘坐电梯 从一楼到十楼,每层楼电梯门都会打开一次,只能拿一次钻石,问怎样才能拿到最大的一颗?
想必好多人都看过这题,网上的解答多种多项,我觉得此题应该考察的是最优解问题,按照最优解的思路,此题没有100%的解决方法,只能尽量使其期望更高,也就是概率更大。这一题可以说是数学和哲学的完美结合,有点像人生,总想得到更多,但又怕后面的都不行,各种纠结啊。。。
总的来说,第五章说来说去都是一个期望的问题。